Your AI Agent Has Amnesia
In a previous post, I wrote about an AI tutoring system that generated identical verb conjugation exercises across every session — grammatically perfect, pedagogically useless. The student scored 100% by memorizing one form while never being tested on the others.
That post focused on harness design. But the deeper issue stayed with me: the system had no memory. It couldn’t ask “have I tested first-person plural yet?” because no record of past exercises existed. Each session started from zero. The agent was brilliant within any single conversation and completely amnesiac across them.
Memory is what turns a stateless tool into something that actually evolves. But the hard part isn’t remembering — it’s forgetting well.
What Memory Actually Does
When I started digging into why my system failed, I realized that “memory” is doing three very different jobs for an agent. Thinking about it by purpose — not by storage mechanism — made everything clearer:
Continuity — “Who is this user?” Preferences, project history, what you’ve built together. Without continuity, every interaction is like onboarding a new contractor. You re-explain your codebase, your naming conventions, your deployment setup. Every. Single. Time.
Context — “What are we doing right now?” The current task, tool results from three steps ago, what the next step is. This is what keeps multi-step workflows from falling apart mid-execution. Most agents handle this tolerably through the conversation window.
Learning — “What worked before?” Past outcomes, failed approaches, successful strategies. This is the one that separates a tool from a collaborator. A tool does what you tell it. A collaborator remembers that the last time you tried approach X, it broke everything.
My verb conjugation bug was a learning failure. The agent had no episodic record of past exercises. It couldn’t cross-reference what it generated this session against what it generated last week. So it defaulted to the most probable output every time — third-person singular, the citation form, the textbook default — and produced identical distributions batch after batch.
Most people build agents with only context memory: the conversation window. That’s like hiring someone with perfect short-term focus but no long-term memory. They’ll do great work today and have no idea what they did yesterday.
The Memory Toolkit
Those three jobs map to four implementation types. I won’t go deep here — the landscape is well-covered elsewhere — but a quick orientation helps.
| Type | What it is | Analogy | Key limitation |
|---|---|---|---|
| In-context | Context window — prompt, history, tool results | Working desk | Wiped every session |
| External | Vector DBs, key-value stores, files | Filing cabinet | Only as good as retrieval |
| Episodic | Logs of past task outcomes | Work journal | Grows unbounded |
| Parametric | Model weights from training | General education | Frozen at training cutoff |
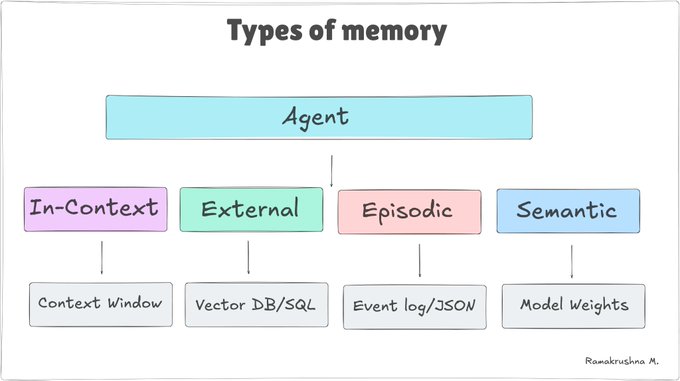 Diagram by @techwith_ram
Diagram by @techwith_ram
Most agents today live entirely in the first row. For a deeper dive on each type with code examples, see @techwith_ram’s excellent breakdown.
The Real Problem — Memory Rots
Building a memory store is a solved problem. Tutorials everywhere. Spin up a vector database, embed your interactions, retrieve on similarity. Done.
The unsolved problem is what happens after fifty sessions.
I learned this the hard way with Claude Code’s auto-memory feature. After twenty-plus sessions on the same project, the memory index — a markdown file that Claude loads at startup — had grown past its useful size. Here’s what it looked like:
- Duplicates accumulated. Three separate sessions noted the same build quirk. Retrieval pulled all three entries, wasting context window on the same information repeated three times.
- Contradictions persisted. I’d switched from Poetry to uv for dependency management weeks ago, but old memory entries still referenced Poetry commands. The agent would suggest
poetry installin a project that had auv.lockfile. - Relative dates rotted. “Yesterday we decided to refactor the path handling” — written three weeks ago. When the agent loaded that entry, “yesterday” pointed to the wrong day, the wrong context, the wrong decision.
- Stale entries misled. Debugging notes about files I’d since deleted. The agent would try to read a config file that hadn’t existed for two weeks, then get confused about why the project structure didn’t match its memory.
The result was an agent that started each session slightly confused, loading contradictory context and outdated facts. It was worse than having no memory at all. At least with amnesia, the agent works from the current state of the world. With rotted memory, it hallucinates about a version of the project that no longer exists.
An ever-growing, unfocused memory store doesn’t make your agent smarter. It makes your agent confidently wrong about the past.
Dreams — REM Sleep for Your Agent
Here’s the metaphor that made this click for me: during the day, your brain absorbs raw input — conversations, observations, sensory data. During REM sleep, it replays events, strengthens what matters, discards what doesn’t. You don’t remember every word of every conversation. You remember the decision, the insight, the correction. Sleep is where consolidation happens.
In Claude Code, auto-memory is the daytime note-taking. The agent jots down things it thinks are important: project structure, user preferences, debugging discoveries. These notes accumulate in a memory file that gets loaded at the start of each session.
Auto Dream is the REM sleep. It runs periodically — triggered after enough elapsed time and enough sessions have accumulated. During a dream cycle, the agent performs structured maintenance on its own memory: it scans existing entries, searches through past session transcripts for high-value signals (corrections, decisions, preference changes), merges duplicates, converts relative dates to absolute ones, deletes facts that have been contradicted by newer information, and prunes the index back down to a useful size.
There’s a critical safety property: during the dream cycle, the agent can only write to memory files. It cannot modify source code or run arbitrary commands. The consolidation process is sandboxed.
Anthropic brought the same concept to their Managed Agents API as Dreams — an async job that reads a memory store plus past session transcripts and produces a reorganized output store. The input is never modified directly. You review the consolidated output before committing it. The same principle: separate the messy accumulation phase from the structured consolidation phase, and let the consolidation run offline.
This is the piece most memory tutorials skip entirely. They show you how to build the filing cabinet. They don’t show you how to keep it from turning into a junk drawer.
From DIY to Managed
Regardless of how you implement consolidation, the essential pattern behind every memory-augmented agent is the same: retrieve before the LLM call, write after it.
Here’s what that looks like with a vector database and the Anthropic SDK:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
import anthropic
import chromadb
client = anthropic.Anthropic()
db = chromadb.PersistentClient(path="./memory")
memories = db.get_or_create_collection("agent_memories")
def run(user_message: str) -> str:
results = memories.query(query_texts=[user_message], n_results=3)
context = "\n".join(results["documents"][0]) if results["documents"][0] else ""
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
system=f"Relevant context from past sessions:\n{context}" if context else "",
messages=[{"role": "user", "content": user_message}],
)
answer = response.content[0].text
memories.add(documents=[f"User: {user_message}\nAgent: {answer[:200]}"],
ids=[f"mem_{hash(user_message)}"])
return answer
This works. Your agent remembers past interactions, retrieves relevant context, and builds up a knowledge base over time. But it doesn’t solve consolidation. After a hundred sessions, that ChromaDB collection is full of duplicates, contradictions, and stale entries, and you’re back to the rotting memory problem.
Anthropic’s Dreams API addresses consolidation as a first-class operation:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
import anthropic
client = anthropic.Anthropic()
store = client.beta.memory_stores.create(name="my-agent-memory")
session = client.beta.sessions.create(
agent=agent_id,
resources=[{"type": "memory_store", "memory_store_id": store.id}],
)
dream = client.beta.dreams.create(
inputs=[
{"type": "memory_store", "memory_store_id": store.id},
{"type": "sessions", "session_ids": [s1.id, s2.id, s3.id]},
],
model="claude-opus-4-7",
instructions="Merge duplicates. Remove stale debugging notes. Keep user preferences.",
)
The retrieval pattern is well-understood. The consolidation problem — knowing what to keep, what to merge, and what to forget — is where the real innovation is happening.
The Bigger Picture
Memory isn’t a feature you bolt on at the end. It’s what turns a stateless tool into something that evolves with you.
The insight most people miss: remembering everything isn’t the goal. A human expert doesn’t remember every conversation they’ve ever had. They remember what matters, let go of what doesn’t, and revise what’s changed. That’s what makes their knowledge useful rather than just large.
My verb conjugation system works now. Same model, same prompt quality. The difference is memory — and the willingness to forget what’s no longer useful. (I wrote more about what the original bug taught me about agentic harnesses if you want the full story.)
The concepts in this post draw from @techwith_ram’s comprehensive breakdown of agentic memory, Anthropic’s Dreams API documentation, and the Claude Code Auto Dream deep-dive on claudefa.st. If you’re building agents that persist across sessions, all three are worth your time.